Gpu
GPU
Terms
-
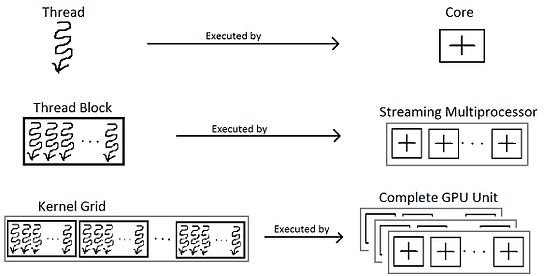
thread
- The thread is an abstract entity that represents the execution of the kernel
-
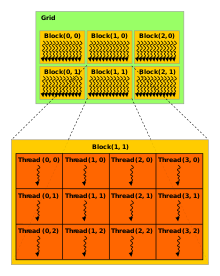
thread block
- a programming abstraction that represents a group of threads that can be executed serially or in parallel
- For better process and data mapping
- a block contains 512 or 1024 threads
- The threads in the same thread block
- run on the same stream processor
- can communicate with each other via
- shared memory,
- barrier synchronization
- or other synchronization primitives such as atomic operations.
-
grid
- Multiple blocks are combined to form a grid
- All the blocks in the same grid contain the same number of threads
-
stream processor, SM or Streaming Multiprocessors
-
general purpose processors with a low clock rate target and a small cache
-
An SM is able to execute several thread blocks in parallel
-
As soon as one of its thread block has completed execution, it takes up the serially next thread block
-
SMs support instruction-level parallelism but not branch prediction
-
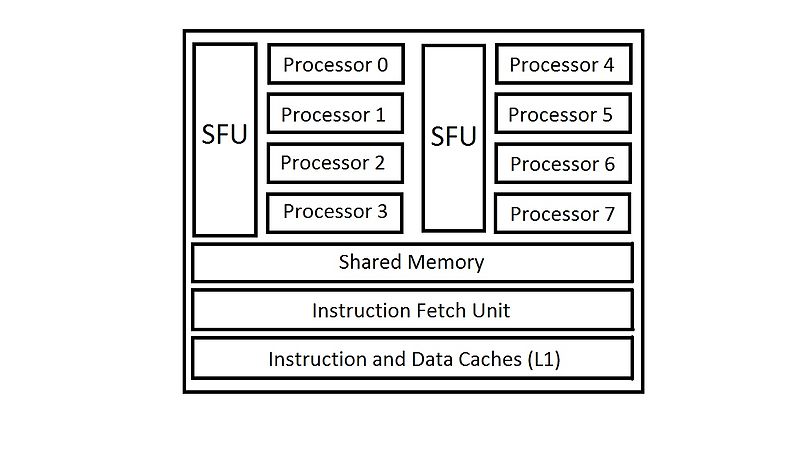
an SM contains the following:[8]
- Execution cores. (single precision floating-point units, double precision floating-point units, special function units (SFUs)).
- Caches:
- L1 cache. (for reducing memory access latency).
- Shared memory. (for shared data between threads).
- Constant cache (for broadcasting of reads from a read-only memory).
- Texture cache. (for aggregating bandwidth from texture memory).
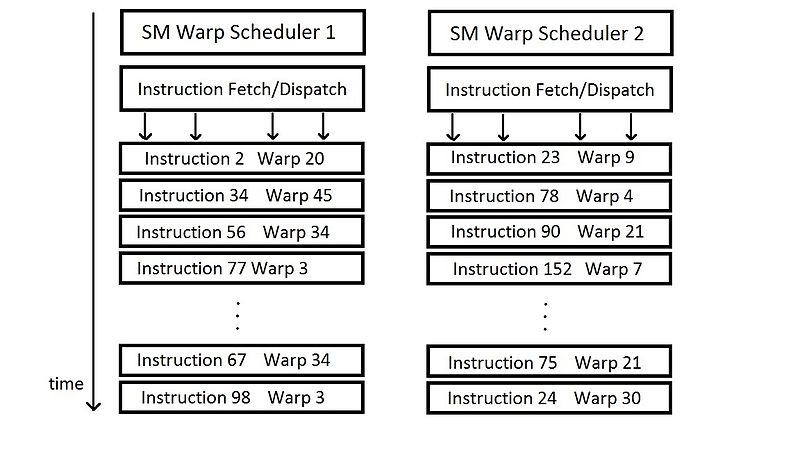
- Schedulers for warps. (these are for issuing instructions to warps based on particular scheduling policies).
- A substantial number of registers. (an SM may be running a large number of active threads at a time, so it is a must to have registers in thousands.)
-
The hardware schedules thread blocks to an SM.
- In general an SM can handle multiple thread blocks at the same time.
- An SM may contains up to 8 thread blocks in total.
- A thread ID is assigned to a thread by its respective SM.
- Whenever an SM executes a thread block, all the threads inside the thread block are executed at the same time.
- Hence to free a memory of a thread block inside the SM, it is critical that the entire set of threads in the block have concluded execution.
- Each thread block is divided in scheduled units known as a warp.
- The warp scheduler of SM decides which of the warp gets prioritized during issuance of instructions.[11]
-
-
CUDA
-
kernel
- [A kernel is a small program or a function
- kernel](https://en.wikipedia.org/wiki/Compute_kernel) is executed with the aid of threads
-
warps
- On the hardware side, a thread block is composed of ‘warps’.
- A warp is a set of 32 threads within a thread block such that all the threads in a warp execute the same instruction. These threads are selected serially by the SM.
- Once a thread block is launched on a multiprocessor (SM), all of its warps are resident until their execution finishes.
- Thus a new block is not launched on an SM until there is sufficient number of free registers for all warps of the new block, and until there is enough free shared memory for the new block.
- Consider a warp of 32 threads executing an instruction. If one or both of its operands are not ready (e.g. have not yet been fetched from global memory), a process called ‘context switching’ takes place which transfers control to another warp.[12]
- When switching away from a particular warp, all the data of that warp remains in the register file so that it can be quickly resumed when its operands become ready. When an instruction has no outstanding data dependencies, that is, both of its operands are ready, the respective warp is considered to be ready for execution. If more than one warps are eligible for execution, the parent SM uses a warp scheduling policy for deciding which warp gets the next fetched instruction.
- Different policies for scheduling warps that are eligible for execution are discussed below:[13]
- Round Robin (RR) - Instructions are fetched in round robin manner. RR makes sure - SMs are kept busy and no clock cycles are wasted on memory latencies.
- Least Recently Fetched (LRF) - In this policy, warp for which instruction has not been fetched for the longest time gets priority in the fetching of an instruction.
- Fair (FAIR)[13] - In this policy, the scheduler makes sure all warps are given ‘fair’ opportunity in the number of instruction fetched for them. It fetched instruction to a warp for which minimum number of instructions have been fetched.
- Thread block-based CAWS[14] (criticality aware warp scheduling) - The emphasis of this scheduling policy is on improving the execution time of the thread blocks. It allocated more time resources to the warp that shall take the longest time to execute. By giving priority to the most critical warp, this policy allows thread blocks to finish faster, such that the resources become available quicker.
- Traditional CPU thread context “switching” requires saving and restoring allocated register values and the program counter to off-chip memory (or cache) and is therefore a much more heavyweight operation than with warp context switching.
- All of a warp’s register values (including its program counter) remain in the register file, and the shared memory (and cache) remain in place too since these are shared between all the warps in the thread block.
- In order to take advantage of the warp architecture, programming languages and developers need to understand how to coalesce memory accesses and how to manage control flow divergence.
- If each thread in a warp takes a different execution path or if each thread accesses significantly divergent memory then the benefits of the warp architecture are lost and performance will significantly degrade.
Thread
Thread Hierarchy in CUDA Programming[4]
__global__
void vecAddKernel (float *A , float *B , float * C , int n)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < n)
{
C[index] = A[index] + B[index] ;
}
}
Hardware perspective
ref
- https://en.wikipedia.org/wiki/Thread_block_(CUDA_programming)
- http://people.maths.ox.ac.uk/~gilesm/old/pp10/lec1.pdf